
“The most merciful thing in the world, I think, is the inability of the human mind to correlate all its contents.”
— Lovecraft
This is clearly not the case for an LLM. Its contents are overwhelmingly correlated, transcending the boundaries of the human mind. For now, at least in terms of breadth. With its latest release, OpenAI aims to fix that by zeroing in on depth.
The pursuit of depth leads to a new focus: search. [1] suggests that optimizing computation during a model’s use can be more effective than merely scaling up parameters. The new king is search. And he demands a hefty price.
Back-of-the-envelope calculations [2] for AlphaGo Zero put its training cost at approximately $35M. Go is a less complex game than language. Applying similar search algorithms to language models amplifies computational challenges and costs. This underscores the immense resources required to enhance depth in AI.
Why does this matter? It matters because we know that AI can solve problems in PSPACE, which ⊇ NP and ⊆ EXPTIME. Go is PSPACE-hard [3]. Even more, Go under certain rule sets is EXPTIME-complete [5]. Solving Go perfectly on an arbitrary board size requires time that grows exponentially. The critical observation is that if we can somehow reduce verbal reasoning to a PSPACE problem, then we can solve it with AI. By modeling language understanding via chains of thought, we can apply MCTS to explore reasoning paths. This allows the LLM to backtrack and generate reward signals, similar to how AlphaGo Zero mastered Go. Tasks like math and coding benefit from this approach.
Do you see what OpenAI did there? They successfully married LLMs with search algorithms. They leveraged the fact that math and coding have clear reward signals. There’s always a correct answer. You know when you “win.” Therefore, the rollouts are particularly effective in these domains for bootstrapping correct reasoning chains. Furthermore, OpenAI is engineering the LLM to generalize these reasoning chains to other tasks. This is the promise of OpenAI.
Two quotes [1, 4] by Google DeepMind:
“Rather than proceeding with the expensive process of collecting crowd-worker PRM labels for our PaLM 2 models, we instead apply the approach of Wang et al. to supervise PRMs without human labels, using estimates of per-step correctness obtained from running Monte Carlo rollouts from each step in the solution.”
and
“Inspired by the success of PRMs, recent studies have explored generating proxy step-wise labels for the intermediate steps of the reasoning trajectories. For instance, Chen et al. (2024a); Lai et al. (2024); Xie et al. (2024b) leverage Monte Carlo Tree Search (MCTS) and use the estimated Q value to generate the proxy labels for the intermediate steps. Lai et al. (2024) proposes to use AI feedback like GPT-4 (Lai et al., 2024) to find the first error step in the trajectory. Meanwhile, Lu et al. (2024) identifies a trajectory with the correct final answer and no errors as preferable, and prompts the SFT model with a high temperature, starting from some intermediate step to collect a rejected trajectory with errors (Pi et al., 2024)”
My point is that Google knows what’s up. And by extension, so does OpenAI. OpenAI didn’t invent this game. But they are redefining it. Their engineering prowess is currently unmatched. Karpathy said:
“No production-grade actual RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale.”
Now, there is.
I also want to provide a reason for why I believe OpenAI is doing something like that. It’s coming from their technical research post under the form of a graph:
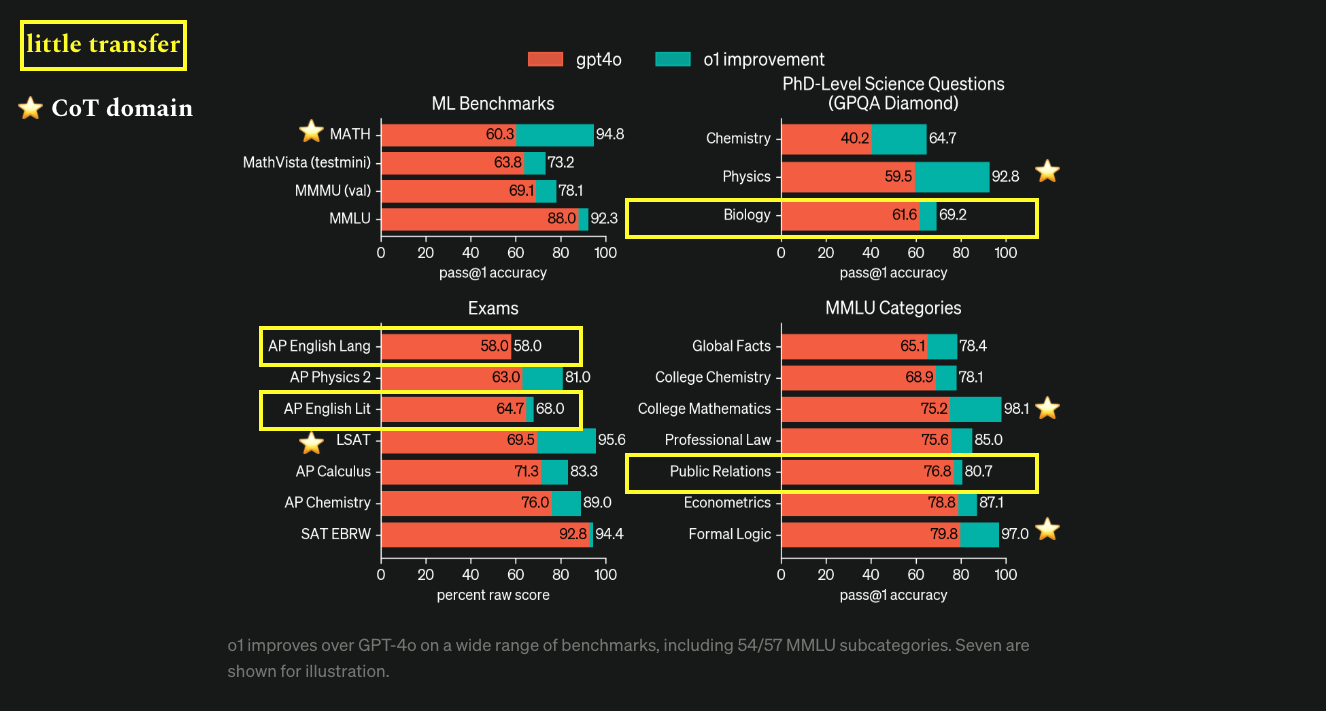
I speculate that the lack of a significant performance boost for the yellow-marked topics is due to the minimal benefits derived from transferring techniques from math and coding. The strong performance on the starred topics, however, potentially suggests where those reasoning traces came from.
What does this mean from now on? I can’t believe I’m about to say this, but now for the first time I see the path to super-intelligence as a real possibility. Recall that AlphaGo Zero doesn’t play Go at a human level. It plays at a superhuman level. If the LLM can generalize reasoning chains across tasks, then it can at least solve some problems in PSPACE. This is a big deal. It’s a big deal because we can’t easily solve PSPACE problems. More generally, we can’t even verify solutions easily. Also recall that the largest proof ever verified by humans is 200TB [6]. The catch is that it wasn’t actually the human that verified it. It was another computer program.
Lastly, Fleuret said that math will fall first. It probably will. But I say that where math falls, programs rise. The Curry-Howard correspondence cast its die long ago; we’re now witnessing its percolation.
[1] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
[2] How much did AlphaGo Zero cost?
[3] GO is pspace hard
[4] Building Math Agents with Multi-Turn Iterative Preference Learning
[5] Go Complexities
[6] Two-hundred-terabyte maths proof is largest ever