
“I worry about this every time I cut my fingernails or have my hair cut — at what point did my Markov blanket become an external state?”
— Friston
Incredible things are happening in the world. And as most of the time, “you can see the future first in San Francisco.”
I have got voraciously dish brain nerd-sniped today. By virtue of how life unfolded, I am a physics nerd, but by virtue of interests, I am comprehensively, almost constitutively nerdy, simply because I was blessed with an insatiable curiosity (which is either a gift or a fairly exhausting neurological condition, depending on the day). I am your Thought Emporium enjoyer on an iPhone 12 in landscape mode while eating a bowl of soup, who covered the subject in at least two occasions (#1, #2) that I know about.
But probably after physics, being interested in consciousness is the runner up. There are things I have not written about yet—drafts in various states of becoming—though a keen eye glancing over the about me section might already pick up the scent. I spent almost 15 years in martial arts in some fairly non-negotiable, identity-level way, and probably around half of that in meditating daily. I am a creature of almost ferocious habit. I learned a few things along the way that language handles about as gracefully as a dictionary handles grief.
Having said that, let me start with Friston, because the man is the legend and the legend is the man. The last thing I have read that had his stamp on it was this.
Let me go briefly through it (this is mostly a rehashed X thread I did back then, so think of this as a primer in FEP).
The free energy principle suggests systems try to minimize “surprise” or prediction error about their world. This minimization, the paper argues, naturally leads to emergent inference (understanding inputs) and learning (updating internal models).
To achieve this, the framework uses “particular partitions”—a way to define a system (like a neuron or brain region) with internal states, sensors, and actuators, all distinct from its environment. These can be layered into “deep partitions,” forming a network.
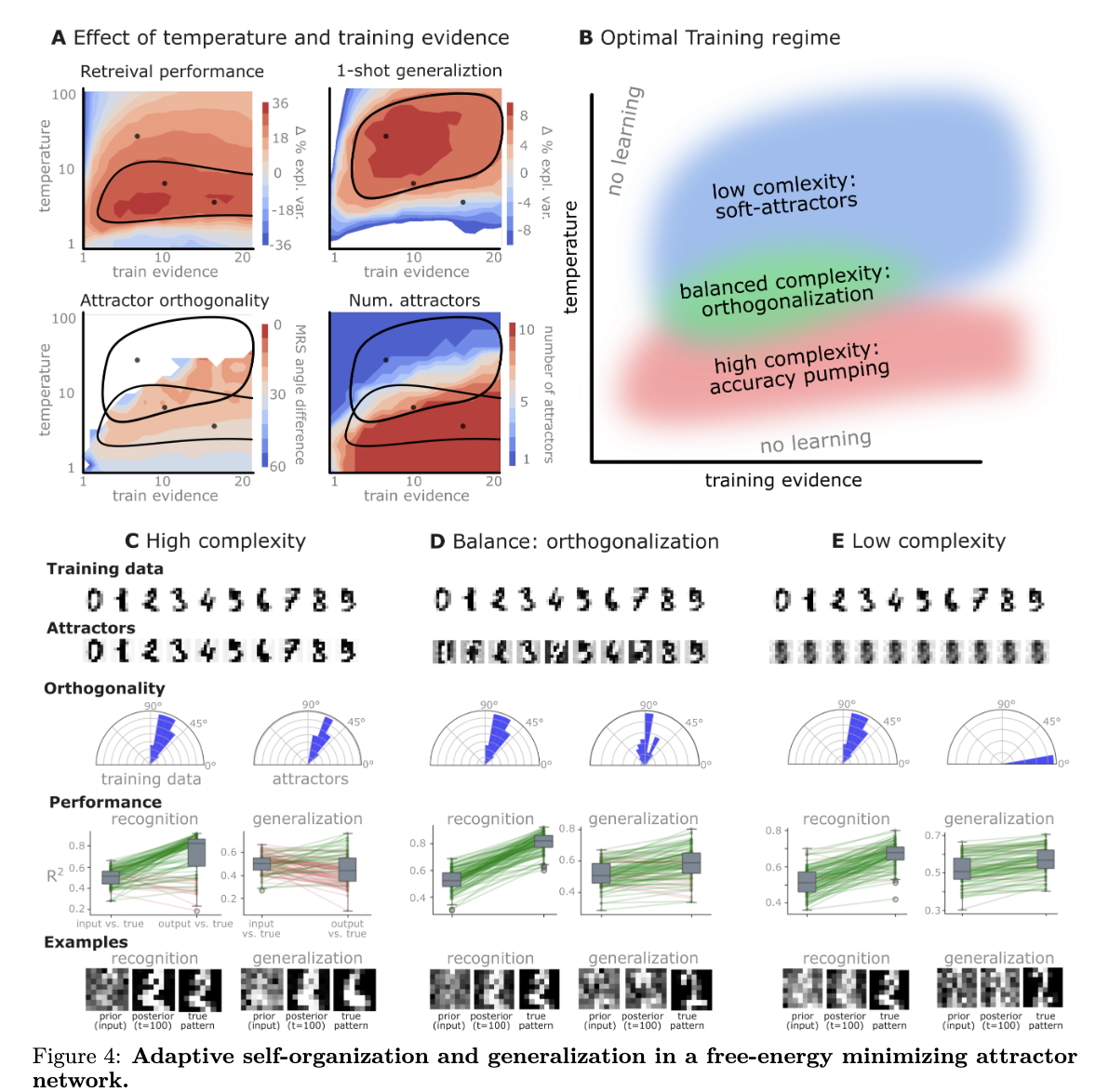
A core finding: these FEP-driven networks spontaneously develop approximately orthogonal attractor states. This means the stable patterns the network learns (its “concepts”) are largely distinct and non-overlapping.
Why is this orthogonalization important?
The orthogonalization enhances the network’s ability to generalize to new, unseen data. It also maximizes information storage and results in a model that is both accurate and parsimonious (less complex).
The learning mechanism itself is fascinating. It is a local, predictive coding-like rule where connections adjust based on how well parts of the network predict each other. This aims to be more biologically plausible than global error signals.
Stochasticity—or randomness in neural updates—is also vital, because it allows the network to explore different possibilities, avoid getting stuck in bad solutions, and perform a more robust form of Bayesian inference—like sampling from “likely explanations.”
Simulations demonstrated these properties: networks formed orthogonal representations from correlated inputs, generalized well to noisy data, learned sequences when inputs were ordered (creating asymmetric connections), and showed resistance to catastrophic forgetting.
Neat! But what the heck does it all mean?
What Cortical Labs are doing is operationalizing Friston’s free-energy principle. Again, that roughly means that biological systems are fundamentally prediction machines trying to minimize “surprise,” which in information-theoretic terms means minimizing the divergence between their internal model of the world and incoming sensory signals.
What had blown me away is how apparently reasonable is the method to tame a clutch of meat. The reward-punishment cycle for biological substrate is feeding the neurons sine waves—a low-entropy signal, ordered, predictable, easy to model—a case where the neurons can then accurately predict what comes next, which is this weird system’s version of “comfort.” Likewise, flood it with high-entropy noise, maximally unpredictable, whenever it misses something and the neurons cannot model this—the system’s version of distress.
If this does not strike you as beautiful, you are a drone, and I have no idea how did you convince yourself to read up until this point.
Anyway, the kicker is that the system is not being “told” anything explicitly. Contrast this to what is happening in deep learning: here, there is no loss function being propagated, no gradient descent, no labeled data.
The neurons appear to self-organize toward behaviors that reduce their exposure to unpredictable inputs, which just happens to correlate with playing Pong better. The environment—the game structure—is the curriculum.
What makes it philosophically vertiginous is the neurocriticality bit mentioned toward the end—the observation that the cells enter a specific dynamical regime (the “edge of chaos,” roughly) specifically when engaged with the task. Sub-critical and they can’t propagate signal; super-critical and they avalanche. The critical state is where interesting computation conceals itself—not unlike the birth of the first heartbeat—and apparently playing a game is what gets them there. Which implies something almost uncomfortably teleological about neurons: they seem to “want” to be in that regime, and structured tasks give them the means to get there.
Reading academic works in this niche domain is not something that I often did. Apparently, these people had a 2022 NeurIPS poster on comparing the sample efficiency of this biological system against reputable, heavily engineered RL algorithms like DQN and PPO. And apparently, those ~800k biological neurons learn Pong faster.
Maybe that is not just a quirk, but a pretty loud signal that there is a fundamentally different and possibly more efficient computational substrate at work here. The no-training/inference distinction that guy keeps hammering feels to me the whole crux of it: there is no separate learning phase followed by a deployment phase. It is one continuous adaptive loop, more like how you actually learn to ride a bike than how a neural net gets trained on bike-riding video.
This is stunning. There is so much to learn.